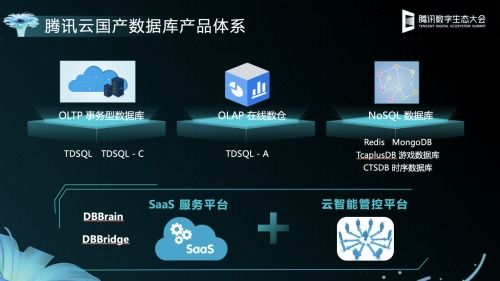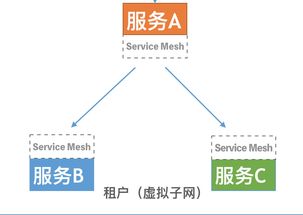
在當今數字化浪潮中,數據處理與存儲作為核心基礎設施,正經歷著一場深刻的變革。阿里巴巴集團副總裁、數據庫領域資深專家李飛飛指出,智能技術、大數據應用與云原生分布式數據庫系統(tǒng)的深度融合,正在重塑數據處理和存儲支持服務的未來圖景。
一、智能化賦能數據庫系統(tǒng)自主優(yōu)化
傳統(tǒng)數據庫管理往往依賴人工干預,面臨性能調優(yōu)復雜、運維成本高昂等挑戰(zhàn)。李飛飛強調,通過引入機器學習、自適應算法等智能化技術,現(xiàn)代分布式數據庫能夠實現(xiàn)自感知、自決策與自優(yōu)化。例如,系統(tǒng)可實時分析查詢模式,自動調整索引策略與資源分配;預測潛在故障并提前進行容錯處理;甚至根據業(yè)務負載動態(tài)彈性伸縮,顯著提升運行效率與穩(wěn)定性。這種智能化內核使得數據庫從“被動工具”轉變?yōu)椤爸鲃踊锇椤保瑸樯蠈討锰峁└咝А⒖煽康臄祿罩巍?/p>
二、大數據驅動下的架構演進
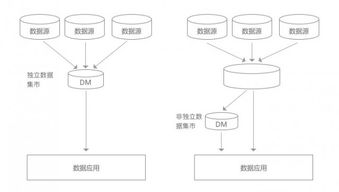
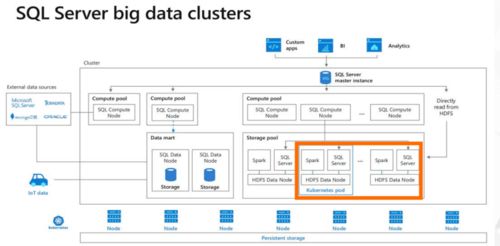
隨著數據規(guī)模爆炸式增長與實時性要求提升,傳統(tǒng)集中式數據庫已難以應對。李飛飛認為,云原生分布式數據庫通過水平擴展、多副本一致性協(xié)議等技術,為海量數據存儲與高并發(fā)訪問提供了基礎。而大數據技術的融入,進一步強化了其分析處理能力——通過集成流計算、圖計算等引擎,數據庫不僅能支撐事務處理(OLTP),還可直接進行復雜分析(OLAP),實現(xiàn)“湖倉一體”與HTAP(混合事務/分析處理)。這打破了數據孤島,讓實時決策與深度洞察成為可能,為企業(yè)數字化運營注入新動力。
三、云原生重構存儲服務范式
“云原生不僅是部署形式的改變,更是設計理念的重構。”李飛飛表示,基于容器化、微服務與聲明式API的云原生分布式數據庫,天然具備彈性伸縮、敏捷迭代與跨環(huán)境可移植性。存儲層依托云基礎設施(如塊存儲、對象存儲),實現(xiàn)了存算分離、資源池化與按需付費。用戶無需關心底層硬件細節(jié),即可獲得高可用、強一致且無限擴展的數據服務。云原生生態(tài)促進了數據庫與DevOps、AI平臺的無縫集成,形成從數據攝入、處理到應用的全鏈路支持體系。
四、融合趨勢下的挑戰(zhàn)與展望
盡管融合前景廣闊,李飛飛也指出仍需攻克諸多難題:如何在分布式環(huán)境下保證數據安全與隱私合規(guī)?如何降低智能算法帶來的不確定性風險?如何平衡性能、成本與易用性?對此,阿里云數據庫團隊正通過軟硬協(xié)同優(yōu)化(如智能網卡、持久內存)、可信計算環(huán)境與自動化運維平臺等實踐探索解決方案。李飛飛預見數據處理將更加“隱形”——智能化的云原生數據庫如同水電煤一樣,成為無處不在卻又無需刻意感知的基礎服務,推動各行業(yè)實現(xiàn)數據價值最大化。
從智能化自治到云原生彈性,從大數據兼容到全場景服務,李飛飛所闡釋的融合路徑,標志著數據庫技術正邁向一個更靈活、更智能、更普惠的新階段。阿里巴巴集團通過云數據庫產品(如PolarDB、AnalyticDB)的持續(xù)創(chuàng)新,不僅支撐了自身業(yè)務生態(tài),更將經驗轉化為標準化服務,助力全球企業(yè)構建面向未來的數據基礎設施。在這一進程中,技術融合不僅是工具升級,更是驅動業(yè)務創(chuàng)新、加速產業(yè)智能化的核心引擎。